2015年6月27日,中国中文信息学会青年工作委员会系列学术活动——知识图谱研究青年学者研讨会在清华大学FIT大楼多功能报告厅召开。本次活动由青工委和中文信息学会语言与知识计算专委会联合举办,旨在推动和促进该领域老师、同学以及爱好者之间的交流。
本次活动邀请到了国内在知识图谱领域在一线工作的9位青年学者进行专题报告,他们是:东南大学漆桂林教授、华东理工大学王昊奋博士、北京师范大学王志春博士、中科院软件所韩先培博士、北京大学邹磊博士、中科院信工所王泉博士、北京大学冯岩松博士、中科院自动化所刘康博士和清华大学刘知远博士。报告会由刘康博士和刘知远博士共同主持。
本地活动共吸引了学术界和产业界近150名老师和同学前来参加,不少老师和同学专程从外地甚至香港赶来。中文信息学会副理事长、秘书长孙乐老师也全程参加了研讨会。
报告会共分为1)知识图谱的自动构建;2)知识图谱的表示学习;3)知识图谱的应用:实体连接、推理及产业应用;4)知识图谱的应用:问答系统四个主题。每个主题邀请2-3位讲者做专题报告,对知识图谱的最新热点问题和研究挑战进行了详细介绍与综述,同时每位老师也提出了当前知识图谱面临的关键问题,为今后知识图谱的研究与应用提供了重要参考意见。上午报告和下午报告结束后分别进行两场别开生面的集中问答。在集中问答环节,每位老师对所提出问题进行了详细解答,同时也对一些关键问题进行了热烈的讨论和交流。整场报告会气氛热烈,交流充分,与会老师和同学均表示收获颇丰。
报告会安排:
|
时间 |
讲者 |
报告题目(Slides下载) |
| 主持人:刘康 | 知识图谱的自动构建 | |
|
09:00-09:30 |
韩先培 | 面向知识图谱构建的信息抽取技术现状、趋势及思考(PPT下载) |
|
09:30-10:00 |
冯岩松 | 常识知识在结构化知识库构建中的应用(PPT下载) |
| 主持人:刘康 | 知识图谱的表示学习 | |
|
10:00-10:30 |
王泉 | 浅谈逻辑规则在实体/关系表示学习中的应用(PPT下载) |
|
10:30-11:00 |
刘知远 | 大规模知识图谱表示学习的研究趋势与挑战(PPT下载) |
| Coffee Break | ||
| 主持人:刘康 | 集中问答 | |
| 11:20-12:20 | 韩先培、冯岩松、王泉、刘知远 | |
| 午饭 | ||
| 主持人:刘知远 | 知识图谱的应用:实体链接、推理与产业应用 | |
|
14:00-14:30 |
漆桂林 | 知识图谱中推理技术及工具介绍(PPT下载) |
|
14:30-15:00 |
王志春 | 多语言知识图谱中的知识链接(PPT下载) |
|
15:00-15:30 |
王昊奋 | 知识图谱关键技术和在行业中的应用(PPT下载) |
| Coffee Break | ||
| 主持人:刘知远 | 知识图谱的应用:问答系统 | |
|
15:50-16:20 |
邹磊 | Natural Language Question Answering Over Knowledge Graph: A Data-driven Approach(PPT下载) |
|
16:20-16:50 |
刘康 | 知识库问答的问题与挑战(PPT下载) |
|
主持人:刘知远 |
集中问答 | |
|
16:50-18:00 |
漆桂林、王志春、王昊奋、邹磊、刘康 | |

与会老师合影

报告现场

韩先培博士

冯岩松博士

王泉博士

刘知远博士
漆桂林教授
王志春博士

王昊奋博士

邹磊博士

刘康博士

上午集中问答

下午集中问答
报告摘要及讲者介绍:
韩先培
报告题目:面向知识图谱构建的信息抽取技术现状、趋势及思考
报告摘要:知识图谱构建的核心任务之一是从海量资源中自动抽取新知识,并将其与图谱中的已有知识融合。作为完成上述任务的核心技术之一,信息抽取在近年来也呈现出新的发展趋势。首先,传统的面向自由文本的信息抽取结果通常包含大量噪音,使得越来越多的信息抽取技术开始转向挖掘容易抽取且明确语义的半结构化或结构化内容;其次,由于大规模知识库如Yago、Freebase等的出现,如何有效利用知识库中现有知识来指导信息抽取成为了新的技术热点,同时也是解决语料瓶颈的有效手段;最后,由于自动方法具有错误,如何验证新知识并估计置信度也成为了知识库构建的一项重点研究内容。围绕上述趋势,本报告将系统介绍信息抽取技术的现状和趋势,同时对信息抽取技术在知识图谱研究中的作用做一些个人思考。
个人介绍:韩先培,博士,中国科学院软件研究所基础软件国家工程研究中心/计算机科学国家重点实验室副研究员。主要研究方向是信息抽取、知识库构建、语义计算以及问答系统。在ACL、SIGIR等重要国际会议发表论文20余篇。韩先培是中国中文信息学会会员及中国中文信息学会青年工作委员会委员。
冯岩松
报告题目:常识知识在结构化知识库构建中的应用
报告摘要:随着知识图谱在各领域的广泛应用,以结构化知识库为核心的新一代信息抽取、文本理解技术进入到了一个崭新的发展阶段。然而单纯以数据驱动的统计机器学习方法仍在模型精度和标注数据依赖性等方面稍显不足,特别是对现有知识资源的挖掘与利用方面并不充分,例如,在地理方面我们都知道,一个国家通常只有一个首都,一城市通常也只能作为一个国家的首都,而一个国家可以包含多个城市,但一个城市却不能包含任何一个国家。这样的“常识”显而易见,但将其应用于结构化知识库的构建过程中,却可以极大地提高知识抽取的准确率。此外,我们还探讨了人们日常生活中的另一种“常识”,即习惯用语和结构化知识库的谓词之间的关系,并应用于知识库问答的问题理解任务中,显著提高了知识问答系统的性能。
个人简介:冯岩松,博士,北京大学计算机科学与技术研究所讲师。2011年毕业于英国爱丁堡大学,获得信息科学博士学位。2011年底至今在北京大学计算机科学与技术研究所工作。主要研究方向包括自然语言处理、信息抽取以及机器学习在自然语言处理中的应用;已连续两年在面向结构化知识库的知识问答评测CLEF-QALD中获得第一名;相关工作已发表在TPAMI、ACL、EMNLP等国际顶级期刊与会议上。同时,作为项目负责人或课题骨干已承担多项国家自然科学基金及科技部863计划项目。在2014年,获得IBM Faculty Award。
王泉
报告题目:浅谈逻辑规则在实体/关系表示学习中的应用
报告摘要:尽管知识图谱为海量信息提供了结构化的存储方式,其符号化的表示形式仍然极大程度地制约了人们对其进行操作与建模,阻碍了其在更多实际任务中的进一步应用。针对这一问题,一种当下流行的研究方向就是将知识图谱中的实体和关系在隐式向量空间中进行表示、建模与学习,从而将实体和关系可计算化,以达到简化知识图谱操作与建模的目的。此类表示学习方法简单、高效,一经推出便受到了学术界的高度关注,在知识抽取、知识推理等相关任务中均得到了广泛应用。然而,此类方法属于单纯数据驱动型方法,在面对精确的抽取和推理任务时往往存在精度不足的缺陷。如何将精确的逻辑规则融入到实体/关系的表示学习之中,成为了当下极具理论和应用价值的研究议题。本次报告将简要介绍实体/关系的表示学习方法,以及近期国内外学者在引入逻辑规则这一方向上的初步研究成果。
个人简介:王泉,博士,中国科学院信息工程研究所助理研究员。2008年在浙江大学理学院获得学士学位。2013年在北京大学数学科学学院获得博士学位。2013年7月至今在中国科学院信息工程研究所信息内容安全技术国家工程实验室工作。研究方向包括机器学习、信息检索、自然语言处理等。作为项目负责人承担国家自然科学基金等科研项目。在SIGIR、IJCAI、ACL、EMNLP、ACM TOIS等国际顶级会议和期刊上发表论文多篇。
刘知远
报告题目:大规模知识图谱表示学习的研究趋势与挑战
报告简介:知识图谱以结构化的形式描述现实世界中实体间的复杂关系,是推动人工智能学科与智能信息服务产业发展的重要基础。如何实现对知识图谱中实体与关系的有效表示,对知识图谱的应用至关重要。最近以分布式表示为理论基础的知识表示取得重大进展,在信息抽取、关系推理等领域取得了重要进展。该报告将介绍知识表示的最新研究进展,总结该技术方案面临的主要挑战,并进一步展望面向大规模知识图谱的知识表示的研究趋势。
个人简介:刘知远,清华大学计算机科学与技术系助理研究员,主要研究领域为表示学习、语义分析与社会计算。2011年7月获得清华大学工学博士学位,博士学位论文“基于文档主题结构的关键词抽取方法研究”获清华大学优秀博士学位论文奖、中国人工智能学会优秀博士学位论文奖,曾获清华大学优秀博士后。作为项目骨干参与多项国家自然科学基金和863项目,在ACM Transactions、IJCAI、AAAI、ACL、EMNLP、COLING等自然语言处理领域著名学术期刊和会议上发表论文十余篇。组织开发的“微博关键词”等社会媒体应用,注册用户已超过350万。曾多次担任ACL、EMNLP等国际会议的程序委员会委员。
漆桂林
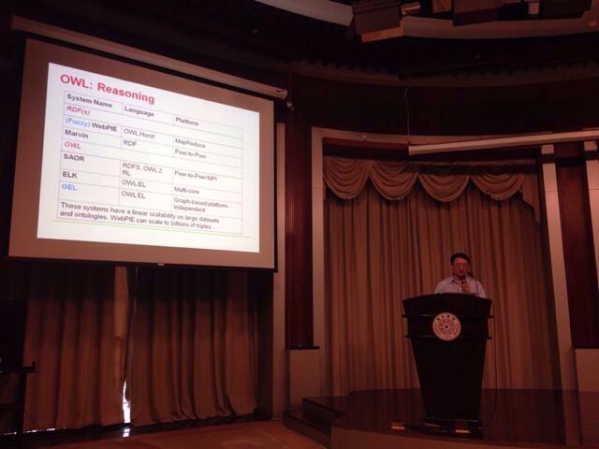
报告题目:知识图谱中推理技术及工具介绍
摘要:本次报告旨在全面介绍知识库推理技术最新进展和推理工具。报告内容覆盖:(1)介绍知识表示和推理的背景;(2)介绍从基于本体的知识推理技术和一些大规模推理工具;(3)介绍基于规则的知识推理技术和规则推理工具;(4)探讨推理技术在知识图谱中的作用;(5)给出知识推理未来发展的一些建议。
个人简介:漆桂林,东南大学计算机科学与工程学院教授,东南大学万维网科学研究所副主任,博士生导师。是澳大利亚Griffith大学访问教授(2011年11月-2012年2月和2013年6月-2013年7月)和法国图卢兹第一大学访问教授(2013年1月-2013年2月)。中国计算机学会会员,ACM专业会员。2006 年获英国贝尔法斯特女皇大学 计算机博士学位,师从国际人工智能专家Weiru Liu 教授和David Bell 教授。2006 年8 月至2009 年8 月,在德国Karlsruhe 大学AIFB 研究所做博士后研究,指导教授是语义Web 创始人之一Rudi Studer 教授。长期从事人工智能和语义网络的推理方面科研及教学工作。发表高质量学术论文90余篇。其中SCI索引21篇(11篇第一作者),EI索引91篇(33篇第一作者)。作为项目负责人承担了两项国家自然科学基金项目。获得欧盟第七框架Marie Curie Actions— International Research Staff Exchange Scheme (IRSES)资助(漆桂林为其中一个workpackage的负责人)。是语义Web 著名杂志Journal of Web Semantics 的编委会成员,是Journal of Advances in Artificial Intelligence 的副主编。主编了国际著名人工智能杂志Annals of mathematics and Artificial Intelligence 的一个特别期刊。是国际语义Web会议ISWC2011年的Poster and Demo track 的联合主席和国际会议EKAW2014年的Poster and Demo track 的联合主席。是国际语义技术联合会议JIST2013的Poster and Demo track 的联合主席和JIST2015的程序委员会主席。是中国语义Web会议2013年大会主席,并担任2009,2012的程序委员会主席。是多个国际研讨会的联合主席。是人工智能著名会议AAAI2014的Senior PC成员。担任多个国际会议和研讨会的程序委员会成员,包括IJCAI(2011-2013),AAAI(2011-2014),KR2012,ECAI2012-2014等。同时是多个国际重要杂志 (Artificial Intelligence Journal、TKDE、Information Science、Journal of Web Semantics、Fuzzy Sets and Systems等)和国内杂志(中国科学、软件学报等)的审稿人。
王志春
报告题目:多语言知识图谱中的知识链接
报告简介:近年来,知识图谱在信息检索、智能问答等多个领域已有了成功的应用;但目前人们主要关注的是单种语言下的知识图谱构建及应用。在以万维网为基础形成的多语言、全球化的信息空间中,人们对跨语言智能信息处理的需求越来越大,因此多语言知识图谱的构建及应用也成为一个值得关注的问题。本次报告将首先介绍目前已有的多语言知识图谱,然后对多语言知识图谱中的知识链接问题展开讨论,介绍本人在该方向取得的研究进展。
个人简介:王志春,北京师范大学信息科学与技术学院副教授,主要研究方向为知识图谱的构建、挖掘及应用。分别于2005年、2010年获天津大学学士、博士学位;2010年4月至2012年1月,在清华大学计算机科学与技术系做博士后研究;2012年2月起,进入北京师范大学工作。近年来,在IJCAI、WWW、ISWC等国际会议发表多篇知识图谱相关的论文。曾担任WWW、ISWC、CSWS等会议的程序委员会委员,以及TKDE、KBS、JCST等期刊审稿人。
王昊奋
报告题目:知识图谱关键技术和在行业中的应用
报告摘要:随着2012年Google提出知识图谱并在Web搜索中引入并获得成功,知识图谱与语义技术受到越来越多业界和学术界的关注。知识图谱除了被应用于语义搜索和问答等应用,其在行业应用尤其是传统行业中也逐步得到使用。本报告将系统地介绍知识图谱在国内外各行各业中取得的成果,并详细介绍其所采用的与知识图谱相关的关键技术。更具体地说,将介绍知识图谱在医疗、金融、电信、数字图书馆等方面的应用初探,并总结出适应于行业应用的知识图谱统一架构。
个人简介:王昊奋,2013年从上海交通大学获得工学博士学位,目前担任华东理工大学讲师。他同时担任计算机技术研究所所长助理和自然语言处理与大数据挖掘研究室副主任等职务。王昊奋在语义技术和图数据管理方面有比较丰富的经验和积累,共发表40余篇高水平论文,其中包括20余篇CCF A类和B类论文。作为技术负责人,他带领团队构建的语义搜索系统在十亿三元组挑战赛(Billion Triple Challenge)中获得全球第2名的好成绩;在著名的本体匹配竞赛OAEI的实体匹配任务中获得全球第1名的好成绩。他带领团队构建了第一份中文语义互联知识库zhishi.me,被邀请参加W3C的multilingual研讨会并做报告。此外,他还作为组织者组织了3届语义搜索研讨会(WWW Workshop SemSearch09, SemSearch10和SemSearch11)和国际语义Web顶级会议ISWC 2010,并长期作为ISWC, WWW, AAAI等国际顶级会议程序委员会委员。他还带领团队参加了百度知识图谱竞赛获得所有任务第一名的好成绩。他主持并参与了多项国家自然科学基金、863国家项目、国家科技支撑相关项目。在就读博士期间,他连续两年获得IBM全球博士精英奖。目前,王昊奋是中文信息学会语言与知识计算委员会委员,NLPCC 2015知识图谱方向主席,并担任CCF ADL55期知识图谱讲师等社会职位。
邹磊
报告题目:Natural Language Question Answering Over Knowledge Graph—-A Data-driven Approach
报告摘要:As more and more RDF data become available on the web, the question of how end users can access this body of knowledge becomes of crucial importance. Although SPARQL is a standard way to access RDF data, it remains tedious and difficult for end users because of the complexity of the SPARQL syntax and the RDF schema. An ideal system should allow end users to profit from the expressive power of Semantic Web standards (such as RDF and SPARQLs) while at the same time hiding their complexity behind an intuitive and easy-to-use interface. Therefore, RDF question/ answering (Q/A) systems have received wide attention in both NLP (natural language processing) and DB (database) areas.
In this talk, besides reviewing some existing work about RDF Q/A in both NLP and DB areas, we introduce our recent work along this direction. Specifically, we design a graph-based RDF Q/A system, called gAnswer, representing a natural language question as a query graph. Then, we answer natural language questions by employing subgraph-matching process. We also present another work, automatically building templates for RDF Q/A, which is based on joining natural language query workloads and SPARQL query workloads.
个人简介:Lei Zou received his BS degree and Ph.D. degree in Computer Science at Huazhong University of Science and Technology (HUST) in 2003 and 2009, respectively. He received a CCF (China Computer Federation) Doctoral Dissertation Nomination Award in 2009 and won Second Class Prize of CCF Natural Science Award in 2014. Since September 2009, he joined Institute of Computer Science and Technology (ICST) of Peking University (PKU) as a faculty member. He has been an associate professor in PKU since August 2012. His recent research interests include graph databases, RDF knowledge graph, particularly in graph-based RDF data management. He has published more than 30 papers, including more than 15 papers published in reputed journals and major international conferences, such as SIGMOD, VLDB, ICDE, TKDE, VLDB Journal.
刘康
报告题目:知识库问答的问题与挑战
报告摘要: 随着搜索引擎的飞速发展,将互联网文本内容结构化,从中抽取有用的概念、实体,建立这些实体间的语义关系,并与已有多源异构知识库进行关联,从而构建大规模知识图谱,对于文本内容的语义理解以及搜索结果的精准化有着重要的意义。然而,如何以自然语言方式访问这些结构化的知识图谱资源,构建知识库问答系统是摆在众多研究者和开发者前的一个重要问题。 本报告将主要介绍知识库问答的主流方法,同时介绍大规模开放域知识库问答所遇到的问题与挑战,以及我们的想法和对策。
个人简介:刘康,博士,中科院自动化所模式识别国家重点实验室副研究员,中国中文信息学会青年工作委员会执行委员。先后于2002年、2005年获得西安电子科技大学学士、硕士学位。2010年于中科院自动化所获得博士学位后留所工作。研究领域包括信息抽取、网络挖掘、问答系统等。在自然语言处理、知识工程等领域国际重要会议和期刊发表论文二十余篇(如TKDE、ACL、IJCAI、EMNLP、COLING、CIKM等),获得KDD-CUP 2011 Track2全球亚军、COLING 2014最佳论文奖、首届“CCF-腾讯犀牛鸟卓越奖”、2014年度中国中文信息学会“钱伟长中文信息处理科学技术奖-汉王青年创新奖”一等奖。同时,作为项目技术负责人,主持了中文百科知识问答、百科知识抽取平台等多个系统的研发,这些系统已经在中国大百科全书出版社、华为等多个企事业单位得到应用。