————————————————————
题目:基于深度学习的聊天机器人综述(PDF)
作者:宫叶云、张奇(复旦)
————————————————————
聊天机器人是根据用户输入的聊天内容,可以自动给出和人类相似聊天行为的聊天系统。聊天机器人作为自然语言处理的核心研究方向之一,与搜索引擎相比,能更有效的为用户从海量信息中提供有用信息,同时具有更佳的人机交互体验,近年来成为研究的热门话题。微软、谷歌和脸书等公司各自推出了不同的聊天机器人产品,并推动聊天机器人作为用户与机器之间新的交互模式不断的发展。聊天内容越开放,聊天内容越长,聊天机器人的回复就越困难。很多公司希望借助自然语言处理和深度学习的技术开发出能够像人一样聊天的机器人,然而目前聊天机器人能够像人一样对话依然有很长的路要走。本文首先介绍聊天机器人面临的挑战,接下来介绍近几年的一些聊天机器人相关的研究工作。
一. 聊天机器人的实现难点
在聊天机器人的实现中面临着各种各样的挑战,其中包括:如何利用好上下文信息,如何解决通用回复问题以及如何评价聊天内容的好坏。
一个好的聊天机器人应该能够结合上下文进行回复。在长对话中,人们可以跟踪说过的话和对话中的信息。如何有效利用长对话中的信息成为研究的热点问题。
聊天机器人中另一个常见的问题是,在基于生成的方法中倾向于生成通用的回复,像“很好”,“我不知道”,这些在大多情况下适用的回复。针对这种问题,很多研究者试图通过改变目标函数来提高回复多样化。
如何评价一个模型结果的好坏同样是聊天机器人实现的一个难点。由于在回复中可能会包含完全不同的单词或者短语,因此机器翻译中常用的评估矩阵ELEU并不适合用来作为聊天机器人的评价矩阵。
二. 聊天机器人的实现方案
聊天机器人的实现方法主要包括基于检索的方法和基于生成的方法。在基于检索的方法中,首先定义知识库,存储需要的回复和一些启发式的方法,根据输入和上下文挑选合适的回复。这里的启发式方法可以是简单的基于规则的表达式去匹配,也可以是复杂的一系列的机器学习方法的组合。在基于检索的方法中不能生成新的文本,只会在固定的回复集中挑选合适的回复。
基于生成的方法不需要依赖于定义好的回复。生成的方法是基于机器翻译自动生成回复,与从一种语言翻译到另一种语言不同的是,这里是从输入翻译到输出,如图一所示。
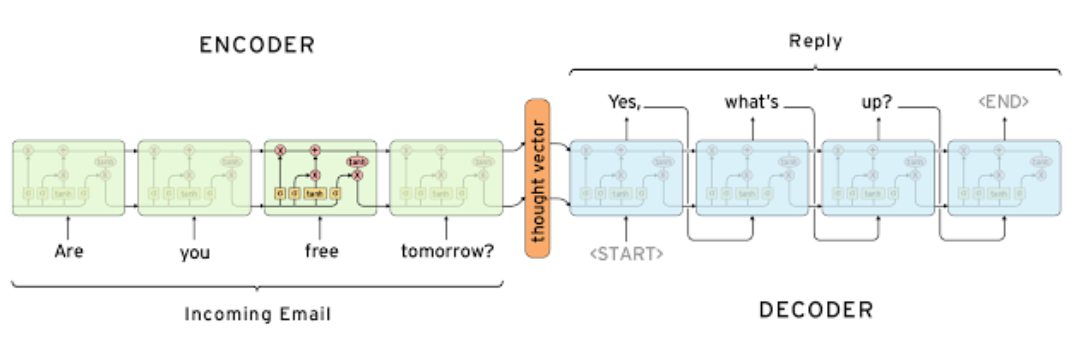
图1. 输入翻译到输出,摘自[7]
两种方法各有利弊。由于基于检索的方法中所有回复检索于现存的知识库,很少会出现语法错误,但是这种方法无法对没有事先定义的情形进行处理。同样这些模型无法考虑在很早之前的会话中出现的实体信息。而基于生成的方法可以回溯到前文讨论的实体,给人感觉像是在和人对话,然而这些模型很难训练,并且很容易使用包含语法错误的句子进行回复。深度学习的方法被广泛应用在基于生成的方法中,接下来我们将主要围绕基于深度学习的生成的方法展开介绍。
聊天机器人已经被广泛的应用到多个领域中,例如虚拟助手,智能客服以及娱乐。传统的方法常常只限定在一个比较窄的领域并且需要大量的人工来抽取特征,在文章End-To-End Generative Dialogue中采用基于循环神经网的方法,省去了大量的人工参与,并在对话任务中取得了优于特征工程方法的结果。这篇文章中针对序列对序列的递归神经网和基于层次的递归神经网进行研究。为了开发出适用不同场景的聊天机器人,文中抽取包含多个不同话题的电影字幕作为对话训练语料。由于在生成模型中存在“通用回复”的问题,例如:“我不知道”可以作为多种不同场景的回复。为了解决“通用回复”的问题,文中采用了改变评价矩阵,在困惑度上增加最大互信息的方法。
在文章Building End-To-End Dialogue Systems Using Generative Hierarchical Neural Network Models中同样采用基于层次的递归神经网络,在大规模的对话语料中进行训练。该模型可以执行自然语言理解,推理,决策和自然语言生成从而复制或者模仿训练语料中的行为。模型不需要事先定义状态和动作的空间表示,这些表示会通过语料以及推理机制和行为生成机制直接学习得到。文章对层次递归神经网络进行扩展使其更好地适合对话任务,通过实验表明使用预训练的词嵌入进行引导和在大规模问题-答案对语料库上对模型进行预训练使结果会有稳定的提高。在该模型中,每一个对话语言被编码成一个稠密的空间向量,然后映射到对话的上下文,用于下一个对话语言中的片段的解码。模型中编码递归神经网络对出现在对话语言中的片段进行编码,上下文递归神经网络将在对话过程中出现的对话语言的时间结构进行编码,从而可以处理长时间内的信息,解码递归神经网络对每个时刻的对话片段进行预测。具体模型如图2所示。
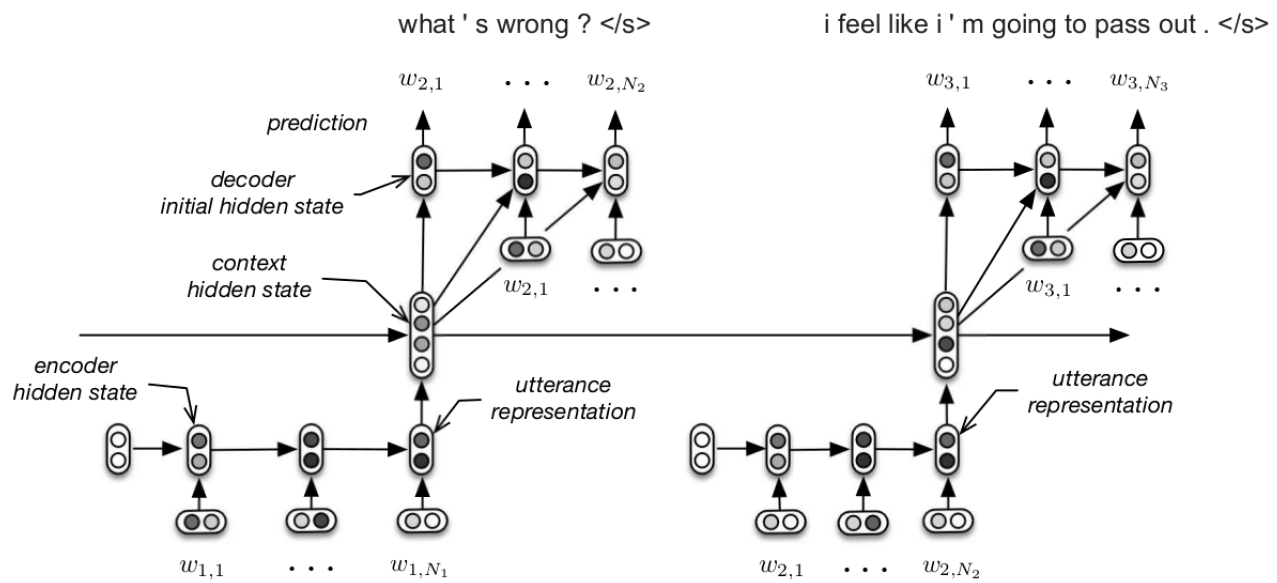
图2. 层次递归神经网图模型
针对聊天机器人中如何很好的利用上下文以及用户历史信息的问题,谷歌在文章Conversational Contextual Cues:The Case of Personalization and History for Response Ranking 中提出一种多损失神经网络模型,该模型融合了多个单损失神经网络模型,每个单损失神经网络模型只对一种特征计算损失,从而达到对上下文,用户等信息分别建模并最终合并多种特征对回复进行预测。在该方法中采用了多个单损失神经网络,每个网络可以单独去度量不同特征在预测中所起到的效果。具体模型如图3(a), 3(b)所示,文中要预测的回复的前一条消息作为输入Input,在前一条消息之前的对话序列作为上下文信息Context,Author表示要进行回复的用户。
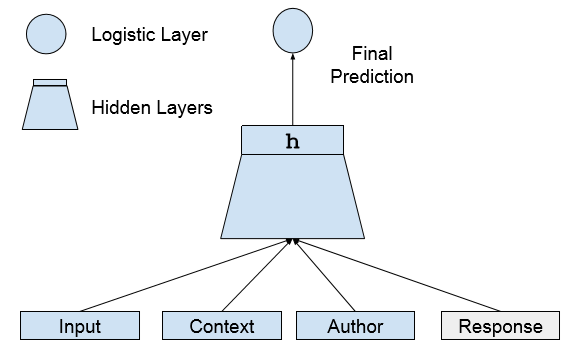
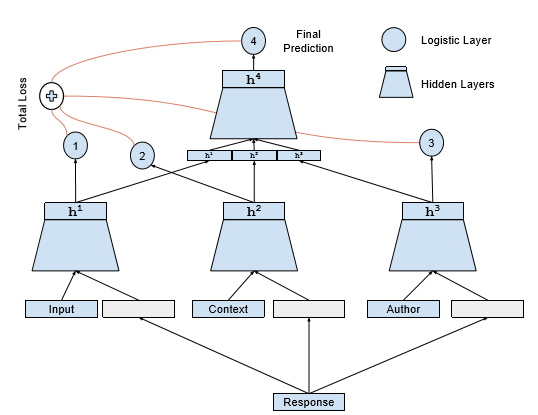
图3(a). 单损失模型 图3(b). 多损失模型
微软在文章:DocChat: An Information Retrieval Approach for Chatbot Engines Using Unstructured Documents中提出一种基于检索的聊天机器人模型,使用不同结构的文档训练不同模型,解决了以往仅仅使用问题-回复对来训练模型的限制,并针对词、短语、句子和篇章等不同级别采用不同方案抽取特征,并通过排名学习模型对最终的回复进行排序。文章在WikiQA和QASent两个语料上的实验结果表明了该方法的适应性。
前面介绍的方法均是针对非目标导向的聊天机器人,非目标导向的聊天机器人假定用户可以开始任意话题的对话。在目标导向的聊天机器人中,输入和输出是受限的,例如关于人工智能的聊天机器人不需要能够讨论体育,只需要完成事先设定的具体任务。脸书公司在文章Learning End-to-End Goal-Oriented Dialog 中针对目标导向的聊天机器人进行了研究,该系统期望去理解用户的需求并通过有限的对话轮次完成明确的目标,并定义了两种不同的评价标准:每一次回复和针对每一个目标的一轮完整对话的正确率作为系统的评价标准。文中以餐馆预订为例,目标是帮助用户预订餐馆。整个任务划分为5个子任务。
- 给定用户的请求的语句,对话系统通过提问问题补全用户请求中缺失的字段。
- 获取任务1中得到的字段后,询问用户是否更改当前查询信息。
- 调用相应API根据用户需求查询结果,并将候选结果列举给用户,直到用户接受为止。
- 提供额外的信息服务。
- 整合所有的对话,返回用户在第三个任务中选择的结果。
文章中分别对基于记忆神经网络的方法、有监督的嵌入模型、基于检索的方法以及基于规则的方法进行了实验,实验表明基于记忆神经网络的方法优于其他方法。
当前聊天机器人主要采用端对端的模型,然而端对端的模型存在着难以评估的问题,最近使用的bAbI任务的测试集规模非常小,因此该任务的方法一般也会是小规模的,针对此类问题,在文章Evaluating Prerequisite Qualities for Learning End-to-End Dialog Systems 中Jesse Dodge等基于(OMDb, MovieLens, Reddit)语料构造了适合大规模的新任务。文中主要设计了问答,推荐,问答和推荐混合以及主题相关的对话等4种不同的任务,来对不同的端对端聊天系统进行评测。
参考文献:
[1] Colton Gyulay, Michael Farraell and Kevin Yang. End-To-End Generative Dialogue. 2016.
[2] RamiAl-Rfou and MarcPickett and JavierSnaider et al. Conversational Contextual Cues: The Case of Personalization and History for Response Ranking. arXiv preprint arXiv:1606.00372, 2016.
[3] Jiwei Li, Will Monroe, Alan Ritter et al. Deep reinforcement learning for dialogue generation. arXiv preprint arXiv:1606.01541, 2016
[4] Iulian V. Serban, Alessandro Sordoni, Yoshua Bengio et al. Building End-To-End Dialogue Systems Using Generative Hierarchical Neural Network Models. AAAI, 2016
[5] Kaisheng Yao, Geoffrey Zweig, Baolin Peng. Attention with Intention for a Neural Network Conversation Model. arXiv preprint arXiv:1510.08565 (NIPS Workshop), 2015
[6] Antoine Bordes, Jason Weston. Learning End-to-End Goal-Oriented Dialog. arXiv preprint arXiv:1605.07683, 2016
[7] http://www.wildml.com/2016/04/deep-learning-for-chatbots-part-1-introduction/
[8] ZhaoYan ,NanDuan ,JunweiBao et al. DocChat: An Information Retrieval Approach for Chatbot Engines Using Unstructured Documents. ACL, 2016
[9] Jesse Dodge, Andreea Gane, Xiang Zhang et al. Evaluating Prerequisite Qualities for Learning End-to-End Dialog Systems. ICLR, 2016